von Marc Pouly und Simone Lionetti
Immer wieder liest man in diesen Tagen von den wahrlich erstaunlichen Fortschritten der Künstlichen Intelligenz. Sie besiegt den Menschen in allen von ihm jemals ersonnenen Strategiespielen, übertrifft menschliche Experten in der medizinischen Diagnostik und macht auch vor unserer Kreativitätsbastion nicht länger halt. Längst werden von KI erschaffene Portraits versteigert und TV-Serien nach deren Drehbuch produziert. In gleichem Masse durchdringt die Künstliche Intelligenz unseren Alltag, sei es beim Freischalten des Smartphones mittels Gesichtserkennung oder beim vorweihnachtlichen Online-Shopping. All diesen Beispielen liegt eine Technologie zugrunde, die wir heute als Neuronale Netze oder Deep Learning bezeichnen, und ihr Durchbruch war alles andere als absehbar.
Theodore Maiman, Vater der Lasertechnologie, bezeichnete seine Erfindung einstmals als «Lösung auf der Suche nach einem Problem». Rund 60 Jahre später stellt wohl niemand mehr die Bedeutung des Lasers für die Sensorik, Medizin oder Kommunikation in Abrede. Ähnlich erinnert sich auch der Schreibende dieses Textes an sein eigenes Informatikstudium zu Beginn der Jahrtausendwende, als der Professor im Hörsaal neuronale Netze ganz nonchalant mit der Bemerkung abhandelte, dass dies sowieso nicht funktionieren würde. Bereits damals blickten neuronale Netze auf eine 60-jährige Historie zurück, und es sollte noch 15 weitere Jahre bis zu ihrem Durchbruch dauern. Alles begann zum Jahreswechsel 2016 – dem Annus Mirabilis der Künstlichen Intelligenz.
2016 – Als Computer das Sehen lernten
Jedes Jahr treten die weltweit führenden Forschungsgruppen in der Bildanalyse an der ImageNet Challenge gegeneinander an. ImageNet ist eine öffentliche Bilddatenbank mit über 14 Millionen Bildern, welche von freiwilligen Helfern in knapp 22’000 Kategorien eingeteilt wurden. Auf diesen Daten werden Modelle trainiert und später auf einem geheim gehaltenen Testset evaluiert. Da viele Bilder Objekte mehrerer Kategorien zeigen, werden sowohl die Top-1 wie auch die Top-5 Fehlerraten der Modelle bestimmt. Bei der Top-5 Evaluation dürfen die Modelle also fünf Kategorien für das Bild vorschlagen, unter denen sich die richtige Zuordnung befinden muss. Abbildung 1 zeigt die Resultate der Wettbewerbsgewinner seit der erstmaligen Durchführung im Jahr 2010. Die menschliche Leistung in der Bestimmung der korrekten Kategorie wird auf eine Top-5 Fehlerrate von 5.1% geschätzt. Am 10. Dezember 2015 verkündete die New York Times den grossen Durchbruch: Eine Künstliche Intelligenz namens ResNet von Microsoft Research gewann die ImageNet Challenge und durchbrach dabei erstmals die Schallmauer der menschlichen Leistung.
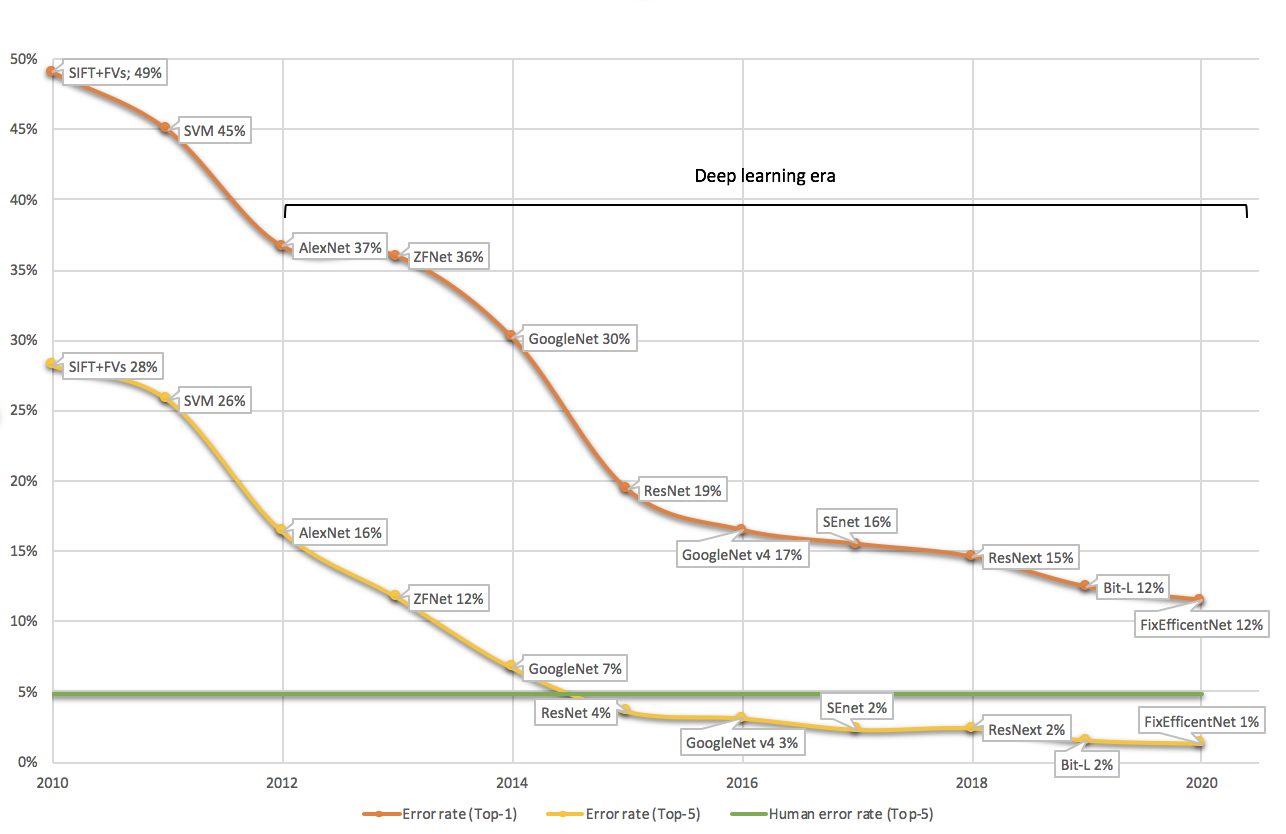
Top-1 und Top-5 Fehlerrate der ImageNet Gewinnerteams seit Beginn des Wettbewerbs im Jahr 2010. Das Top-1 Resultat von 2011 wurde nicht erhoben.
Ein digitales Bild ist eine Zahlenmatrix pro Farbkanal, woraus eine Abbildung auf 22’000 unterschiedliche Kategorien erstellt werden muss. Dieses elementare Verständnis pulverisiert ein verbreitetes Vorurteil gegenüber der modernen Künstlichen Intelligenz, nämlich dass es sich dabei um ein von Menschen erdachtes Regelwerk handelt. Bei einer durchschnittlichen Auflösung von 482x418 Pixel pro Bild mit drei Farbkanälen in ImageNet müsste der Mensch also aufgrund von 604'428 Zahlen dem Computer einprogrammieren, wie ein Dalmatiner von einer Perserkatze zu unterscheiden ist. Ein hoffnungslosen Unterfangen!
Deep Learning Revolution
In den frühen Jahren der ImageNet Challenge konnten selbstlernende Algorithmen keine rohen Pixelwerte verarbeiten. Die Support Vector Machine, das damals erfolgreichste Verfahren, war also darauf angewiesen, dass in einem Vorverarbeitungsschritt charakteristische Bildmerkmale mittels Bildfiltern extrahiert wurden, welche sie dann auf Kategorien abzubilden lernte. Sie war also auf Gedeih und Verderb von der Auswahl geeigneter Bildfilter durch den menschlichen Programmierer abhängig. Rückblickend kamen diese Systeme nie an die für industrielle Anwendungen geforderte Leistungsfähigkeit heran. Den Wendepunkt markierte das Jahr 2012, als mit AlexNet erstmals ein Deep Learning Verfahren die ImageNet Challenge gewann, und zwar gleich mit einer Verbesserung um 10% in der Top-5 Fehlerrate gegenüber der Support Vector Machine als Vorjahresgewinnerin.
Mit Neuronalen Netzen zum Paradigmenwechsel
Deep Learning basiert auf sogenannten Neuronalen Netzen, einem durch das biologische Neuron inspirierte Verfahren des Maschinellen Lernens, dessen Grundzüge bereits 1943 von einem Neurophysiologen und einem Mathematiker skizziert wurden. Ein einzelnes künstliches Neuron, wie in Abbildung 2 dargestellt, wendet eine nichtlineare Transferfunktion auf eine gewichtete Summe seiner Inputwerte an. Nun werden tausende solcher künstlichen Neuronen in Schichten angeordnet, so dass der Output einer früheren Schicht den Input einer späteren Schicht liefert. Die Gewichte aller einzelnen Neuronen bilden dabei die Parameter des Systems, deren Werte in einem sehr rechenintensiven Trainingsprozess unter Zuhilfenahme bereits kategorisierter Trainingsdaten ermittelt werden.
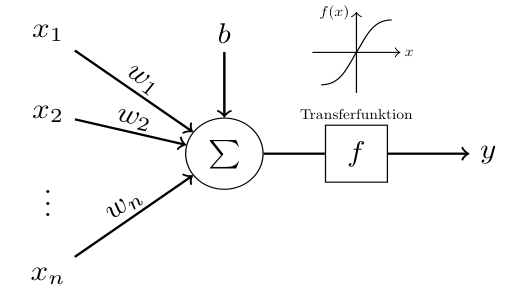
Ein künstliches Neuron berechnet eine nichtlineare Funktion einer gewichteten Summe seiner Eingabewerte, y=f(w1x1+⋯+wn xn+b), wobei xi die Eingabewerte und wi die aus den Trainingsdaten gelernten Gewichte darstellen.
Werden die gelernten Gewichte über die verschiedenen Schichten hinweg visualisiert, so fällt auf, dass frühere Schichten eigenständig primitive Bildstrukturen zu erkennen lernen und damit die Bildfilter imitieren. Der entscheidende Unterschied liegt also darin, dass neuronale Netze diese Bildfiltern selbstständig aus den Daten lernen. In späteren Schichten werden diese Informationen automatisch zu komplexeren Merkmalen kondensiert und schlussendlich auf eine Wahrscheinlichkeitsverteilung über die möglichen Bildkategorien abgebildet. Computer begannen also die menschliche Leistungsfähigkeit zu übertreffen, nachdem sie von der expliziten Eingabe menschlichen Wissens befreit werden konnten.
Big Business in Artificial Intelligence
Nicht nur für uns Menschen gehört das Sehen zu den wichtigsten Voraussetzungen, um erfolgreich mit unserer Umgebung interagieren zu können. Als eine Künstliche Intelligenz namens AlphaGo 2017 den damalige Weltmeister Ke Jie im Brettspiel GO schlug, war dies zweifellose eine Meisterleistung und damit ein historisches Ereignis in der Entwicklung der Künstlichen Intelligenz. Das zuverlässige Kategorisieren und Segmentieren von Objekten auf Bildern hat aber ungleich weitreichendere Bedeutung, sei es für die medizinischen Diagnostik, für autonome Fahrzeuge, die automatisierte Schädlingsbekämpfung in der Landwirtschaft oder für die optische Qualitätskontrolle in der produzierenden Industrie. So gesehen markiert der Durchbruch von 2016 in der Bildanalyse auch gleichzeitig den Beginn von Big Business in Artificial Intelligence.
Aktuelle Herausforderungen und Entwicklungen
Neuronale Netze berechnen ihre Resultate aufgrund von Millionen von Parametern, welche zuvor in einem oftmals tagelangen Rechenprozess unter Miteinbezug von zehntausenden durch Menschen annotierte Daten festgelegt wurden. Zurecht stellt sich dabei die Frage, was ein neuronales Netz nun tatsächlich gelernt hat und inwiefern sich dieses gegenüber Menschen erklären lässt. Handelt es sich bei der Anwendung um eine optische Entriegelungsfunktion einer Katzentür, so sind die meisten Kunden durchaus gewillt, diese Intransparenz zu akzeptieren. Interessanterweise stimmt diese Aussage sogar für höchst sicherheitsrelevante Systeme. Vielleicht nutzen auch Sie die Smartphone Gesichtserkennung für den Zugriff auf Ihre privaten Daten und vertrauen damit einem neuronalen Netz, dessen erlerntes Wissen sich nicht einmal seinen Entwicklern erschliesst. Weitaus differenzierter gestaltet sich diese Beziehung in medizinischen Anwendungen. Zu Recht ist die Erklärbarkeit von Modellen eines der aktivsten und dringendsten KI Forschungsfelder, insbesondere im Hinblick auf die medizinische Zulassung solcher Verfahren.
Eine weitere Herausforderung ergibt sich aus dem beinahe unstillbaren Datenhunger moderner Deep Learning Modelle. Mit zunehmender Anzahl Neuronen und Schichten steigt gleichsam die Anzahl Optimierungsparameter, und je mehr Parameter durch den Trainingsprozess optimiert werden müssen, desto mehr Trainingsdaten und Rechenressourcen müssen zur Verfügung stehen. ResNet, der ImageNet Gewinner von 2015, hatte rund 60 Millionen Optimierungsparameter. Vor wenigen Wochen veröffentlichten Microsoft und Nvidia ein neuronales Sprachmodell mit über 500 Milliarden Optimierungsparametern.
Somit stellt sich zurecht die Frage, inwiefern diese Technologie überhaupt in unseren Unternehmen zum Einsatz kommen kann. Die Antwort liefert die wohl wichtigste Entwicklung für die Industrialisierbarkeit von Künstlicher Intelligenz in den letzten Jahren. So wie wir unseren Kindern das Lesen und Schreiben in der Schule beibringen, um junge Erwachsene später im Lehrbetrieb domänenspezifisch auszubilden, lassen sich diese Modelle auf riesigen, allgemeinen Datenbanken vortrainieren. Wir bezeichnen dieses Vorgehen als Transfer Learning. Google, Facebook und Co. stellen mittlerweile ganze Bibliotheken von vortrainierten Modellen zur Verfügung, die wir mit wenigen Tagen Aufwand und überschaubaren Datenmengen anwendungsspezifisch anpassen können. Zur Illustration: Das initiale Training von GPT-2 vom November 2019 mit immerhin 1,5 Milliarden Optimierungsparametern würde auf einer modernen Cloud Infrastruktur schätzungsweise 35'000 Euro kosten, während das Transfer Learning des vortrainierten Modells mit lediglich 300 Euro zu Buche schlägt.
Mittlerweile haben neuronale Netze weitestgehend alle anderen Verfahren der Künstlichen Intelligenz für die Verarbeitung von unstrukturierten Daten wie Bilder, Texte, Video und Audio verdrängt. Dabei werden auch wir Forschenden tagtäglich von neuartigen und innovativen Anwendungen überrascht. Stellen Sie sich vor: Sie sitzen im Restaurant, zücken Ihr Smartphone, fotografieren den servierten Teller und ein neuronales Netz schreibt Ihnen das Kochrezept – mit Zutatenlisten, detaillierten Mengenangaben und Zubereitungsinstruktionen. Schon 2019 hat Facebook ein Modell veröffentlicht, das genau dazu in der Lage ist. Schlussendlich war es jedoch die brillant einfache Idee des Transfer Learnings, welche den Datenhunger der KI gezähmt und damit ihre breite industrielle Nutzung, insbesondere auch für unsere KMUs als Rückgrat und Innovationsmotor der Schweizer Wirtschaft, erst möglich gemacht hat.